
📉 O que é overfitting e underfitting em IA
Se você está aprendendo Inteligência Artificial, é bem provável que já tenha esbarrado nos termos overfitting e underfitting. Mas o que eles significam na prática? E como identificá-los em um projeto real?
Neste post, vamos explicar de forma simples o que são esses conceitos — e mais importante — como evitá-los, com exemplos em Python para te ajudar a visualizar o problema com clareza.
🤖 O que é Overfitting?
Imagine que você está treinando um modelo para prever preços de casas. Se ele “decorar” os dados de treino ao invés de aprender padrões reais, temos um problema: overfitting.
👉 Em outras palavras:
Overfitting acontece quando o modelo aprende muito bem os dados de treinamento, a ponto de não generalizar bem para novos dados.
🎯 Sinais de overfitting:
- Alta precisão nos dados de treino;
- Baixa precisão nos dados de teste;
- O modelo é complexo demais para o problema.
🤖 E o que é Underfitting?
Já o underfitting é o oposto. Aqui, o modelo é simples demais para capturar os padrões nos dados. É como tentar prever o clima só olhando o mês do ano — falta contexto, falta inteligência.
👉 Em resumo:
Underfitting acontece quando o modelo não consegue aprender bem nem os dados de treinamento.
🎯 Sinais de underfitting:
- Baixa precisão em treino e teste;
- O modelo parece “perdido”, mesmo com muitos dados;
- Ele está menos complexo do que deveria.
🔍 Exemplo prático com Python
Vamos ver um exemplo usando sklearn com regressão polinomial para visualizar tanto o underfitting quanto o overfitting:
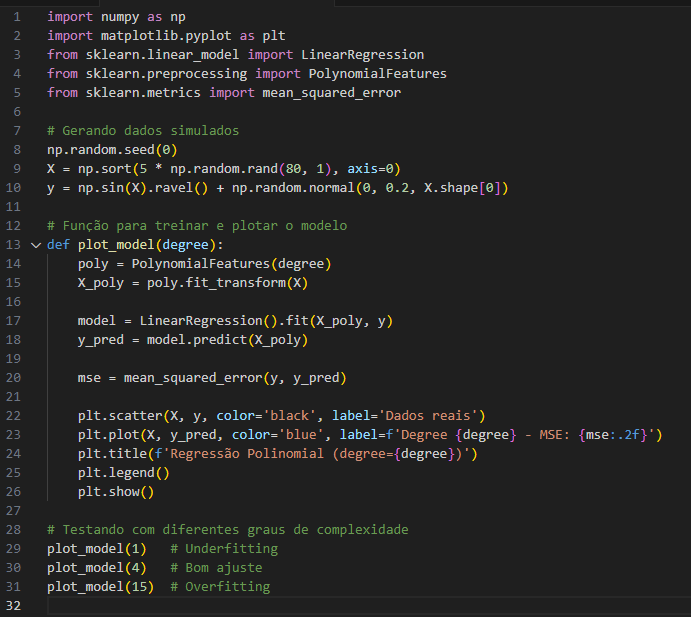
🧠 O que esse código mostra?
- Degree 1 (reta): o modelo não consegue capturar a curva → underfitting.
- Degree 4: o modelo acompanha bem os dados → bom ajuste.
- Degree 15: o modelo “oscila demais” tentando seguir cada ponto → overfitting.
🧩 Como evitar overfitting e underfitting?
A chave está no equilíbrio. Aqui vão algumas práticas comuns:
Contra o overfitting:
- Usar validação cruzada (cross-validation);
- Reduzir a complexidade do modelo;
- Aplicar regularização (L1, L2);
- Coletar mais dados, se possível.
Contra o underfitting:
- Testar modelos mais complexos;
- Adicionar mais features relevantes;
- Ajustar os hiperparâmetros com cuidado.
📌 Conclusão
Entender overfitting e underfitting é essencial para quem trabalha com modelos preditivos. Um bom modelo de IA não é aquele que tira 10 na prova que já viu, mas o que sabe resolver questões novas com confiança.
💡 Dica final: sempre visualize seus dados e resultados. Às vezes, um gráfico revela o que números sozinhos não conseguem mostrar.
Qualquer entre em contato com a gente no formulário abaixo: